
Cube 4×4×4
3 unique shapes · 10 physical pieces · 64 voxels
A flat-piece 4×4×4 cube built from ten thin polyomino pieces (4 + 4 + 2 copies of three shapes). The denser search space — over half a million collision checks — is still solved in 40 milliseconds, while a human would need more than a month of focused work.
How AI finds the solution
1. Camera → 3D model
Three orthogonal photos of every piece are turned into a digital 3D model using Analysis-by-Synthesis — every mathematically possible polycube is rotated and projected back into theoretical silhouettes, and the one with the highest Jaccard IoU against the photo masks wins.



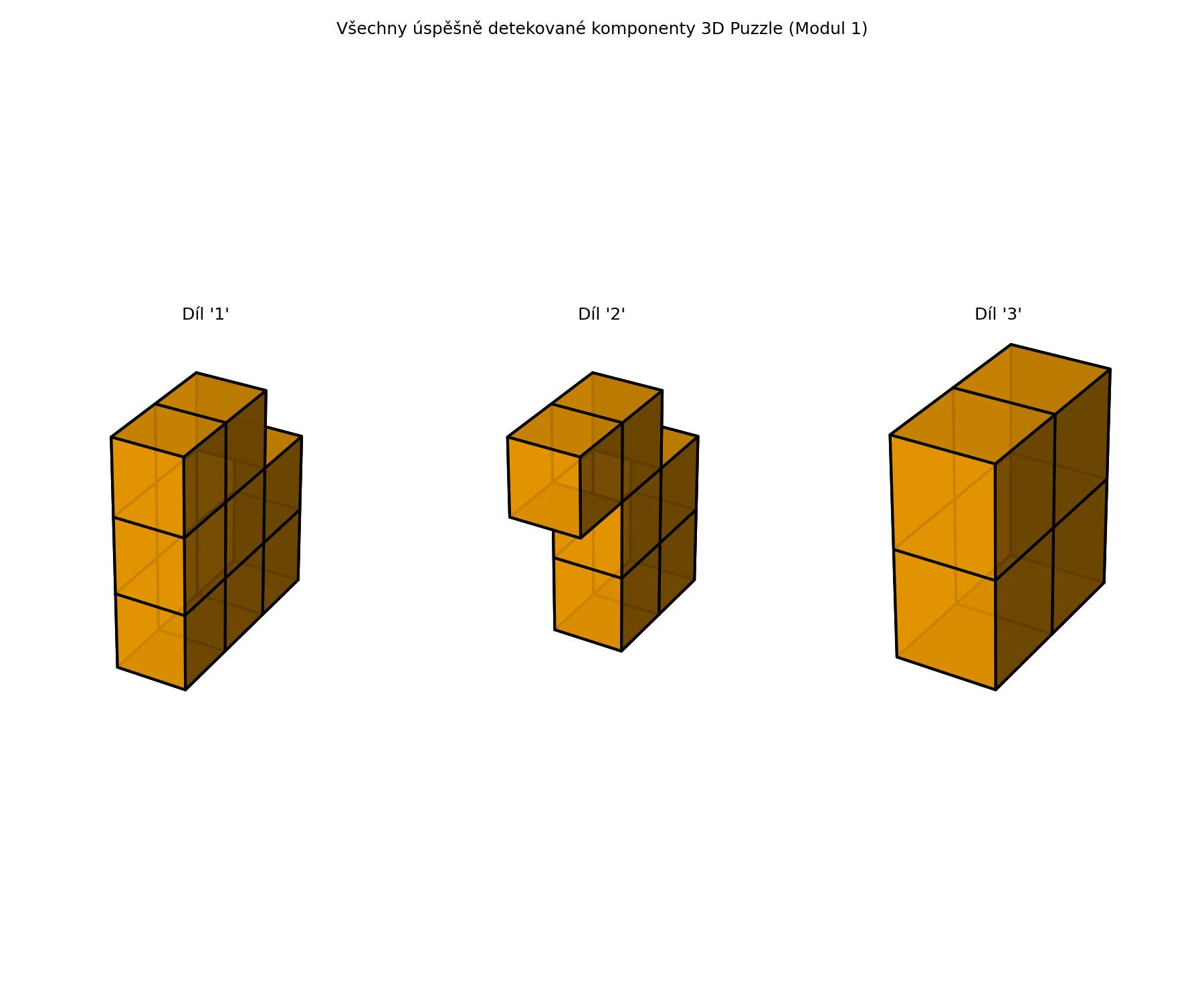
2. Backtracking solver
A bitmask DFS solver fills the cuboid voxel-by-voxel using the First-Empty-Cell heuristic and symmetry-breaking for duplicate pieces. Each placement is a single CPU bitwise-AND collision check.
And the cube assembles itself

| Target cuboid | 4 × 4 × 4 |
|---|---|
| Unique piece types | 3 |
| Total physical pieces | 10 |
| Computer Vision phase | 5.98 s |
| Solver phase | 0.039 s |
| Backtrack iterations | 570 016 |
| Solutions found | 1 |
| Time for a human (8 h/day) | 39.6 days |
Step-by-step guide
1. Photograph every piece
Take three orthogonal photos (front, side, top) of each unique piece on a contrasting background. Save them as 1a.jpg, 1b.jpg, 1c.jpg, 2a.jpg, …
2. Write config.yaml
Declare the cuboid size, the segment count of each unique piece, and how many physical copies of each you have. The optional thickness flag massively speeds up flat puzzles.
cuboid:
x: 4
y: 4
z: 4
thickness: 1
pieces:
"1": 4
"2": 4
"3": 2
segments:
"1": 8
"2": 6
"3": 4
3. Computer Vision phase
cv_shape_matcher.py iterates over all polycubes matching the segment count, projects each rotation into three theoretical silhouettes, and picks the one with the highest IoU against the photo masks. The result is written to pieces.json.
4. Solver phase
solver.py compresses the build box into a single 27- or 64-bit integer. Each piece placement becomes a single bitwise AND collision check, so the inner loop runs at native CPU speed.
5. Run the pipeline
One command runs both phases and writes a 3D visualisation plus a statistics report into the output folder.
python main.py puzzle2Why is AI so much faster?
Three optimisations carry the weight: bitmask collisions (a single CPU instruction instead of a loop), the First-Empty-Cell heuristic (cuts the branching factor by an order of magnitude), and grouping identical pieces (eliminates n! redundant permutations).
Try it yourself
All source code is MIT-licensed and freely available.